In my research, I am constantly running the same computation over every combination of month-day-year-hour in a given sample’s time period. Traditionally, this can be done using loops, like so:
R:
k = 2008 # year start
j = 1 # month start
i = 1 # day start
h = 1 # hour start
# start nested loops:
for (k in 2008:2010) {
for (j in 1:12) {
for (i in 1:31) {
for (h in 1:24) {
print(paste('The date is ',paste(j,i,k,sep='/'),' hour ',h,sep=''))
}}}}
However, there is a cleaner, more efficient way to go. That is, to write a function that takes the day, month, year, etc. as input parameters, and call it using apply(). For a great explanation and introduction to using apply(), sapply(), lapply(), and other derivatives of apply(), see this excellent poston Neil Saunders blog: “What You’re Doing is Rather Desperate”.
To follow our silly example from above, we could create a function that prints the date and hour:
dateprint = function(MM,DD,YR,HR) {
print(paste('The date is ',paste(MM,DD,YR,sep='/'),' hour ',HR,sep=''))
}
Then we could call the function as follows:
k = c(2008:2010) # year range
j = c(1:12) # month range
i = c(1:31) # day range
h = c(1:24) # hour range
# Call function using apply() and defined parameters
output = apply(expand.grid(j,i,k,h), 1,
function(x,y,z,a) dateprint(x[1],x[2],x[3],x[4]))
# Apply stores the output as a list
# I like to convert it to a dataframe for easier viewing and manipulation.
output=data.frame(output)
Notice that you are essentially giving apply() an “input matrix” created by expand.grid(); apply() takes parameters from each row of that “input matrix” and feeds them to our dateprint() function. You can tell apply() to take parameters from each column by changing the “1” to a “2” within your call of apply().
I am not too close with the back end of R, so I am not certain that using apply() will increase the computational efficiency of your code. That said, it is another approach to solving a common problem, and one I use often. Furthermore, it cleans up your code a scintilla.
Clean code = happy code.

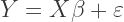

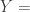
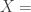
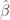
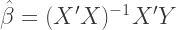
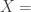










 is the white noise error term, and
is the white noise error term, and 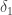 is the effect of the treatment on the treated — the shift shown in the diagram. To be clear, the coefficient on
is the effect of the treatment on the treated — the shift shown in the diagram. To be clear, the coefficient on  is the value we are interested in (i.e.,
is the value we are interested in (i.e., 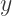

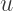 Falling Between
Falling Between 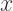 and
and 
